Waybackurls: A Importância de Entender Como as Ferramentas Funcionam
Muitos bug hunters perdem uma energia valiosa e depositam uma expectativa enorme em estratégias incorretas, e é por isso que acabam se frustrando tanto na procura por bugs.
Você já parou para pensar, por exemplo, em quantos bug hunters você já viu utilizar o waybackurls com a esperança de encontrar dados sensíveis diretamente nos documentos retornados?
A chance disso ocorrer, seguindo o fluxo normal de uso, é realmente muito, muito pequena. E neste artigo, vou te explicar o porquê.
Primeiro, vamos alinhar o que realmente é o web.archive.org e, por extensão, o waybackurls. O web.archive é, na sua essência, um crawler que armazena o histórico de URLs publicamente acessíveis.
Isso é incrivelmente valioso.
Significa que, ao utilizar ferramentas como o waybackurls, você consegue fazer uma busca por URLs de forma passiva (passive crawling). É uma adição poderosa ao seu arsenal, permitindo que você colete um grande número de URLs históricas sem a necessidade de varrer ativamente o alvo com ferramentas como gospider ou linkfinder, o que poderia levar ao bloqueio do seu IP ou sobrecarga do sistema do cliente.
Veja um exemplo de execução simples do waybackurls:
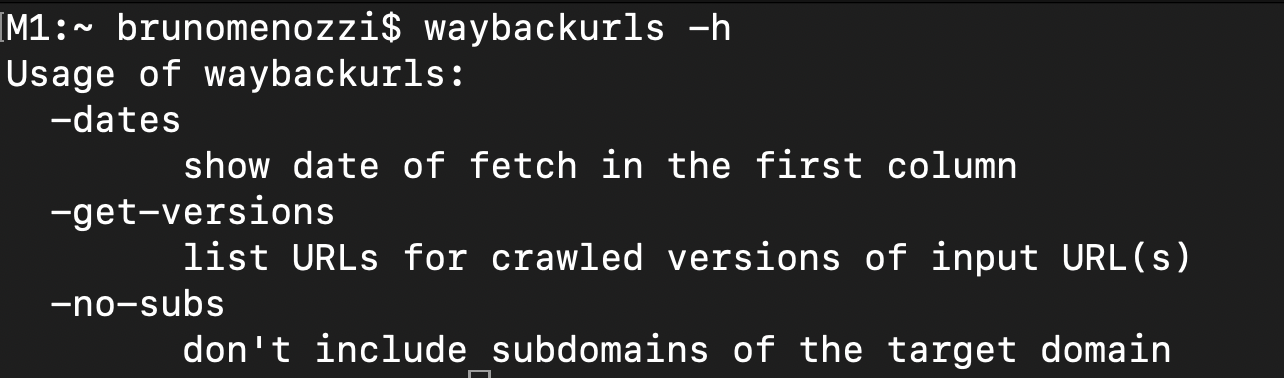
Pense assim: sabe aquele endpoint de API que uma empresa usou anos atrás e decidiu remover do frontend porque estava trazendo muitos problemas de segurança? Então, será que eles tiraram do backend também? Podemos achar esse /api/v2/search e ver o que ele nos traz.
No entanto, é crucial entender que, por mais que essas ferramentas sejam úteis, elas não substituem uma análise ativa e um entendimento profundo do alvo.
A expectativa de muitos é que, ao analisar as saídas do waybackurls ou de ferramentas similares, eles encontrarão aquele documento mágico com “dados_usuario_john.pdf” que revele informações sigilosas. E, ao abrir tal PDF, a ilusão de um vazamento de dados é quase instantânea.
Mas vamos ser diretos: se um link como site.com/dados_usuario_john.pdf retorna dados, e foi acessível por um crawler público como o web.archive, você precisa dar dois passos para trás e respirar.
Pense: onde esse documento REALMENTE deveria estar? E esses dados, são realmente sigilosos, ou mais provavelmente são dados de teste ou demonstração?
A chance de um crawler público ter acesso a algo genuinamente sigiloso e que não deveria estar exposto é mínima. Ele só foi indexado porque, em algum momento, estava acessível publicamente no site, sem a necessidade de autenticação. O web.archive não invade sistemas; ele apenas arquiva o que foi exposto.
Para sermos eficientes, precisamos saber o que esperar de cada ferramenta. Entender as fontes de dados de waybackurls e gau, por exemplo, é fundamental (e essa mentalidade se aplica a outras ferramentas também).
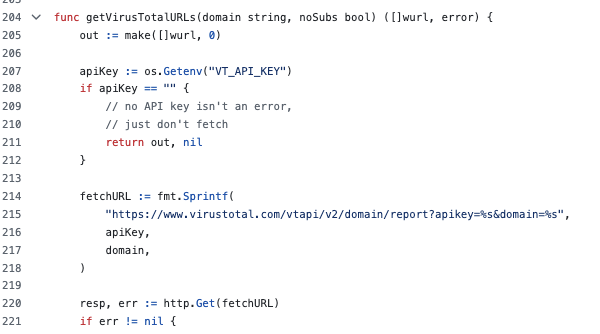
Observe como o waybackurls se integra com diferentes APIs em seu código. Primeiro, a integração com o VirusTotal:
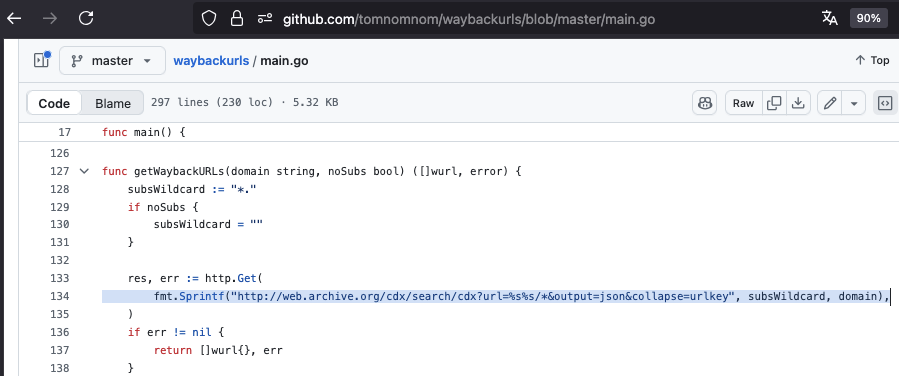
E aqui, a integração com o web.archive.org:
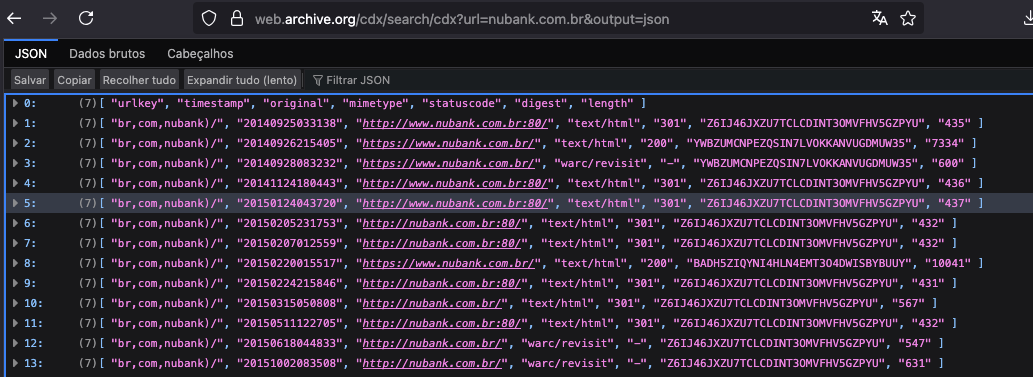
A API CDX do web.archive.org retorna dados em um formato específico que as ferramentas processam. Veja um exemplo de como esses dados podem ser estruturados:
Para o gau, as fontes também são diversas e podem ser exploradas de diferentes maneiras. Veja as opções de provedores que o gau oferece:
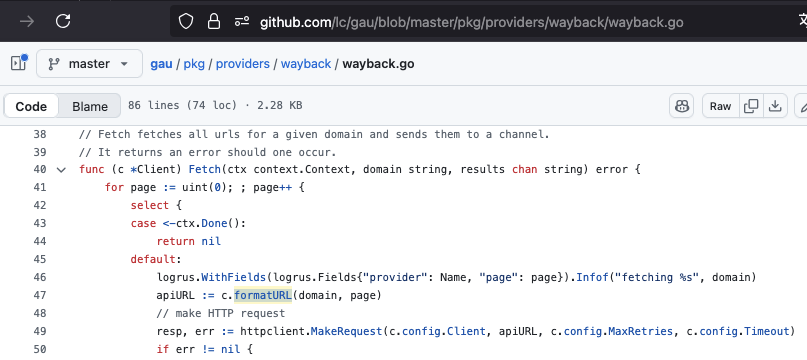
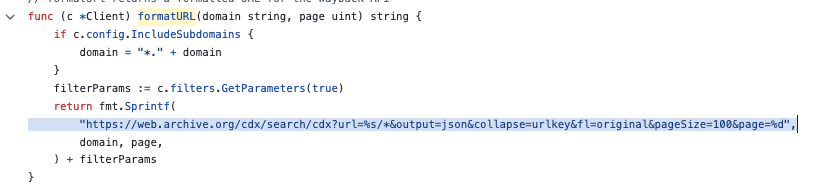
Um exemplo da chamada do gau para o web.archive.org pode ser visualizado em duas partes:
| Ferramenta | Fonte/API | Requer Autenticação? | Descrição |
|---|---|---|---|
| waybackurls | Wayback Machine (Internet Archive) | Não | Busca URLs históricas e versões arquivadas de websites. |
| Common Crawl | Não | Pesquisa URLs em grandes conjuntos de dados da web rastreados publicamente. | |
| VirusTotal API | Sim | Consulta domínios para encontrar URLs maliciosas ou relacionadas a ameaças. | |
| gau | Wayback Machine (Internet Archive) | Não | Coleta URLs de arquivos históricos da web. |
| Common Crawl | Não | Extrai URLs de rastreamentos públicos da web. | |
| AlienVault OTX | Não | Procura URLs e indicadores de comprometimento em dados de inteligência de ameaças. |
E o AlienVault OTX? Também pode conter URLs pré-populadas de investigações reais, mas o VirusTotal se mostra mais consistentemente valioso para esse fim específico - suas análises de sandbox frequentemente capturam artefatos únicos que interagiram com seu alvo. Por isso, focaremos nele como exemplo principal.
Note que as grandes fontes de URLs históricas (Wayback Machine, Common Crawl, AlienVault OTX) não exigem autenticação.
Isso reitera o ponto: elas fornecem acesso a dados que, por sua natureza, já foram publicamente acessíveis. Dados pré-populados de usuários, especialmente aqueles mais valiosos, normalmente são limitados a um número menor de usuários ou a contextos específicos.
A exceção notável entre as fontes padrão do waybackurls é a API do VirusTotal, que requer uma API Key.
E aqui está a provocação: quantos bug hunters que usam o waybackurls configuram e utilizam realmente essa API Key para o VirusTotal?
Ah, então todo este artigo é para dizer que você deve colocar a API Key, rodar e vida que segue, certo? NÃO! Eu estou dizendo que é interessante você buscar, inclusive, por outros serviços que fazem esse mesmo papel de achar dados pré-populados. É preciso verificar as ferramentas que você usa e ver se suas expectativas realmente estão alinhadas. Caso contrário, você somente será um script kiddie reportando comportamentos esperados e se frustrando com o resultado!
Em uma das minhas procuras a bug bounty, o cenário se desenrolou de uma maneira que exemplifica o valor de uma mentalidade crítica. Eu estava revisando as saídas de uma API que retorna dados pré-populados de usuários (geralmente são esses serviços de sandbox, como é o caso do VirusTotal, ou outros endpoints específicos que porventura indexem essas informações). Em meio a milhares de URLs, encontrei uma que parecia interessante:
https://servico.alvo.com/profile?id=usuario123&data=informacao_do_usuario_aqui
Ao abrir essa URL, tive acesso a uma página de um serviço que a empresa de bug bounty oferece aos seus usuários. Em primeiro momento, a minha preocupação não foi “o que eu consegui acessar”, mas sim “qual o contexto em que eu estava? Quais tecnologias estavam presentes ali? Eu consegui ter acesso não autenticado apenas usando os parâmetros certos?”
Minha análise revelou que aquela página não pertencia apenas a um único usuário, mas sim que eu estava utilizando os parâmetros corretos para abri-la. O serviço em si não estava vulnerável a um vazamento de dados generalizado, mas a forma como ele interpretava e processava aqueles parâmetros abria uma porta.
Essa URL, pré-populada por um usuário, me deu um ponto de partida para um fuzzing direcionado. Eu nunca pensaria em chegar àquele serviço ou àquela combinação de parâmetros por métodos convencionais. Mas, com a URL em mãos, comecei a manipular os parâmetros. Não demorou muito para eu encontrar um parâmetro escondido que, quando manipulado corretamente, me resultou em uma recompensa de $3000 dólares!
Após a minha Prova de Conceito (POC), observei que era possível alterar os dados daquela URL e até remover as informações do usuário. Mas a verdade é que, sem aquela URL “pré-populada” como base, eu nunca, mesmo fazendo fuzzing cego, acertaria a quantia exata e os parâmetros necessários para abrir aquela página específica e explorar a vulnerabilidade.
Você já deve ter sentido algo tipo: “Por que eu nunca tive acesso a esse tipo de informação antes? Por que as pessoas não falam tanto disso?”. Eu não vou te dizer que te mostrando tudo isso que mostrei vai fazer você virar o próximo bug hunter milionário com uma Ferrari. Mas existe um certo apego por parte da comunidade às suas metodologias. As pessoas não costumam compartilhar muito O QUE ESTÁ DANDO CERTO PRA ELAS e fazendo elas ficarem ricas.
Eu vou ser sincero mais uma vez contigo, assim como sou diariamente com meu grupo VIP: nesse post aqui eu não falei realmente as APIs que eu uso para coletar URLs pré-populadas de usuário, e eu nunca falei para ninguém. É por isso que eu sempre falo que meu objetivo no grupo VIP é CRIAR UMA MENTALIDADE CRÍTICA E OFENSIVA. Se você sempre viver com a cabeça em ferramentas, você sempre vai estar seguindo a metodologia de uma outra pessoa e nunca se fazendo esse tipo de pergunta que eu trouxe para você neste artigo todo.
Pare de seguir o fluxo da maioria. Comece a questionar. Comece a pensar diferente.
Se você gostou do que leu e quer ter acesso a conteúdos ainda mais aprofundados, com didática exclusiva e um ambiente onde todas as suas dúvidas são levadas a sério, você precisa fazer parte do Grupo VIP.
É lá que compartilhamos a saga completa em primeira mão.